Fixture Monkeyでテストを簡単かつ便利に

"Write once, Test anywhere"
Fixture Monkeyは、Naverがオープンソースとして開発しているテストオブジェクト生成ライブラリです。この名前は、NetflixのオープンソースツールであるChaos Monkeyにインスパイアされたようです。テストフィクスチャをランダムに生成することで、カオスエンジニアリングを実践的に体験できます。
約2年前に初めて出会って以来、私のお気に入りのオープンソースライブラリの一つとなりました。これまでに2つの記事も書きました。
バージョンアップごとに変更が多く、追加の記事は書いていませんでしたが、バージョン1.xがリリースされた今、新たな視点で再訪することにしました。
以前の記事はJavaをベースにしていましたが、今回は現在のトレンドに合わせてKotlinで書いています。この記事の内容は公式ドキュメントに基づいており、実際の使用経験から得た洞察も加えています。
Fixture Monkeyが必要な理由
従来のアプローチでどのような問題があるか、以下のコードを見てみましょう。
例ではJava開発者に馴染みのあるJUnit5を使用しましたが、個人的にはKotlin環境ではKotestをお勧めします。
data class Product (
val id: Long,
val productName: String,
val price: Long,
val options: List<String>,
val createdAt: Instant,
val productType: ProductType,
val merchantInfo: Map<Int, String>
)
enum class ProductType {
ELECTRONICS,
CLOTHING,
FOOD
}
@Test
fun basic() {
val actual: Product = Product(
id = 1L,
price = 1000L,
productName = "productName",
productType = ProductType.FOOD,
options = listOf(
"option1",
"option2"
),
createdAt = Instant.now(),
merchantInfo = mapOf(
1 to "merchant1",
2 to "merchant2"
)
)
// テスト目的に比べて準備プロセスが長い
actual shouldNotBe null
}
テストオブジェクト生成の課題
テストコードを見ると、アサーションのためにオブジェクトを生成するだけで多くのコードを書かなければならないと感じます。実装の性質上、プロパティが設定されていないとコンパイルエラーが発生するため、意味のないプロパティでも書かなければなりません。
テストコードでアサーションのための準備が長くなると、コード内のテスト目的の意味が不明瞭になることがあります。このコードを初めて読む人は、意味のないプロパティにも隠れた意味があるかどうかを確認する必要があり、このプロセスは開発者の疲労を増加させます。
エッジケースの認識の難しさ
プロパティを直接設定してオブジェクトを生成する場合、さまざまなシナリオで発生する可能性のある多くのエッジケースが見落とされがちです。
val actual: Product = Product(
id = 1L, // idが負の値になったらどうなる?
// ...省略
)
エッジケースを見つけるためには、開発者はプロパティを一つ一つ設定して確認する必要がありますが、実際にはランタイムエラーが発生して初めてエッジケースに気づくことが多いです。エラーが発生する前にエッジケースを簡単に発見するためには、オブジェクトのプロパティをある程度ランダムに設定する必要があります。
オブジェクトマザーパターンの問題
テストオブジェクトを再利用するために、オブジェクトマザーパターンと呼ばれるパターンでは、オブジェクトを生成するファクトリークラスを作成し、そのクラスから生成されたオブジェクトを使用してテストコードを実行します。
しかし、この方法はテストコードだけでなくファクトリーの管理も継続的に必要であり、エッジケースの発見には役立ちません。
Fixture Monkeyの使用
Fixture Monkeyは、上記の再利用性とランダム性の問題をエレガントに解決します。どのようにこれらの問題を解決するか見てみましょう。
まず、依存関係を追加します。
testImplementation("com.navercorp.fixturemonkey:fixture-monkey-starter-kotlin:1.0.13")
Kotlin環境でFixture Monkeyがスムーズに動作するようにするためにKotlinPlugin()を適用します。
@Test
fun test() {
val fixtureMonkey = FixtureMonkey.builder()
.plugin(KotlinPlugin())
.build()
}
先ほど使用したProductクラスを使って再度テストを書いてみましょう。
data class Product (
val id: Long,
val productName: String,
val price: Long,
val options: List<String>,
val createdAt: Instant,
val productType: ProductType,
val merchantInfo: Map<Int, String>
)
enum class ProductType {
ELECTRONICS,
CLOTHING,
FOOD
}
@Test
fun test() {
val fixtureMonkey = FixtureMonkey.builder()
.plugin(KotlinPlugin())
.build()
val actual: Product = fixtureMonkey.giveMeOne()
actual shouldNotBe null
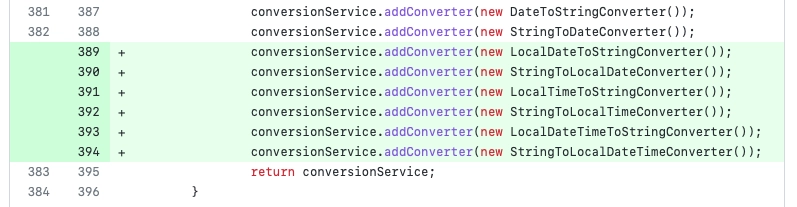
}
不要なプロパティ設定なしにProductのインスタンスを作成できます。すべてのプロパティ値はデフォルトでランダムに埋められます。
 複数のプロパティがうまく埋められる
複数のプロパティがうまく埋められる
ポストコンディション
しかし、ほとんどの場合、特定のプロパティ値が必要です。例えば、例ではidが負の数として生成されましたが、実際にはidは正の数として使用されることが多いです。次のようなバリデーションロジックがあるかもしれません:
init {
require(id > 0) { "idは正の数である必要があります" }
}
テストを数回実行した後、idが負の数として生成されるとテストが失敗します。すべての値がランダムに生成されるため、予期しないエッジケースを見つけるのに特に役立ちます。

ランダム性を維持しつつ、バリデーションロジックが通るように範囲を少し制限しましょう。
@RepeatedTest(10)
fun postCondition() {
val fixtureMonkey = FixtureMonkey.builder()
.plugin(KotlinPlugin())
.build()
val actual = fixtureMonkey.giveMeBuilder<Product>()
.setPostCondition { it.id > 0 } // 生成されたオブジェクトのプロパティ条件を指定
.sample()
actual.id shouldBeGreaterThan 0
}
テストを10回実行するために@RepeatedTestを使用しました。

すべてのテストが通ることがわかります。
様々なプロパティの設定
postConditionを使用する際は、条件を狭めすぎるとオブジェクト生成がコスト高になることに注意してください。これは、条件を満たすオブジェクトが生成されるまで内部で生成が繰り返されるためです。このような場合、特定の値を固定するためにsetExpを使用する方がはるかに良いです。
val actual = fixtureMonkey.giveMeBuilder<Product>()
.setExp(Product::id, 1L) // 指定された値のみ固定され、他はランダム
.sample()
actual.id shouldBe 1L
プロパティがコレクションの場合、sizeExpを使用してコレクションのサイズを指定できます。
val actual = fixtureMonkey.giveMeBuilder<Product>()
.sizeExp(Product::options, 3)
.sample()
actual.options.size shouldBe 3
maxSizeとminSizeを使用すると、コレクションの最大サイズと最小サイズの制約を簡単に設定できます。
val actual = fixtureMonkey.giveMeBuilder<Product>()
.maxSizeExp(Product::options, 10)
.sample()
actual.options.size shouldBeLessThan 11
他にも様々なプロパティ設定方法があるので、必要に応じて探索してみてください。
結論
Fixture Monkeyは、ユニットテストを書く際の不便さを本当に解消してくれます。この記事では触れませんでしたが、ビルダーに条件を作成して再利用したり、プロパティにランダム性を追加したり、開発者が見逃しがちなエッジケースを発見するのに役立ちます。その結果、テストコードが非常に簡潔になり、Object Motherのような追加コードが不要になり、メンテナンスが容易になります。
Fixture Monkey 1.xのリリース前でも、テストコードを書くのに非常に役立ちました。今や安定版となったので、ぜひ導入してテストコードを書く楽しさを味わってください。


 なんてこった!
なんてこった! 幸いなことに、私たちのパンドラの箱には0と1だけが含まれており、他の困難や挑戦はありません。
幸いなことに、私たちのパンドラの箱には0と1だけが含まれており、他の困難や挑戦はありません。