[Spring Batch] KafkaItemReader
· 2分の読み時間

情報
この記事を書く前にDockerを使ってKafkaをインストールしましたが、その内容はここでは扱いません。
KafkaItemReaderとは..?
Spring Batchでは、Kafkaトピックからデータを処理するためにKafkaItemReaderが提供されています。
簡単なバッチジョブを作成してみましょう。
例
まず、必要な依存関係を追加します。
dependencies {
...
implementation 'org.springframework.boot:spring-boot-starter-batch'
implementation 'org.springframework.kafka:spring-kafka'
...
}
application.ymlにKafkaの設定を行います。
spring:
kafka:
bootstrap-servers:
- localhost:9092
consumer:
group-id: batch
@Slf4j
@Configuration
@RequiredArgsConstructor
public class KafkaSubscribeJobConfig {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final KafkaProperties kafkaProperties;
@Bean
Job kafkaJob() {
return jobBuilderFactory.get("kafkaJob")
.incrementer(new RunIdIncrementer())
.start(step1())
.build();
}
@Bean
Step step1() {
return stepBuilderFactory.get("step1")
.<String, String>chunk(5)
.reader(kafkaItemReader())
.writer(items -> log.info("items: {}", items))
.build();
}
@Bean
KafkaItemReader<String, String> kafkaItemReader() {
Properties properties = new Properties();
properties.putAll(kafkaProperties.buildConsumerProperties());
return new KafkaItemReaderBuilder<String, String>()
.name("kafkaItemReader")
.topic("test") // 1.
.partitions(0) // 2.
.partitionOffsets(new HashMap<>()) // 3.
.consumerProperties(properties) // 4.
.build();
}
}
- データを読み取るトピックを指定します。
- トピックのパーティションを指定します。複数のパーティションを指定することも可能です。
- KafkaItemReaderでオフセットを指定しない場合、オフセット0から読み取ります。空のマップを提供すると、最後のオフセットから読み取ります。
- 実行に必要なプロパティを設定します。
ヒント
KafkaPropertiesは、SpringでKafkaを便利に使用するためのさまざまな公開インターフェースを提供します。
試してみる
さて、バッチジョブを実行すると、application.ymlの情報に基づいてconsumer groupsが自動的に作成され、ジョブがトピックの購読を開始します。
kafka console producerを使って、testトピックに1から10までのデータを追加してみましょう。
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test
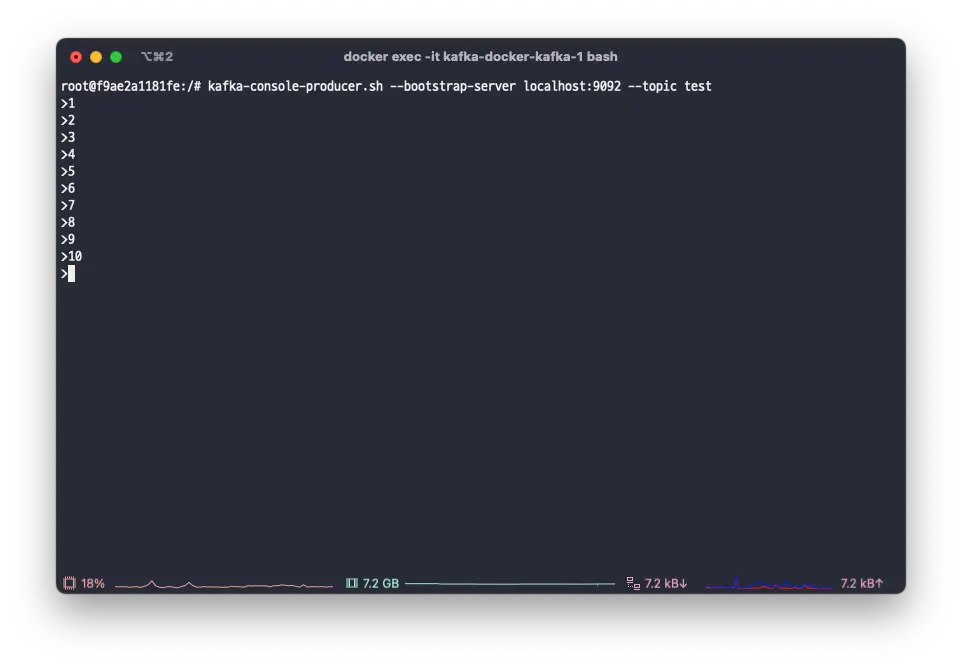
バッチジョブがトピックを正常に購読していることがわかります。

chunkSizeを5に設定したので、データは5件ずつバッチ処理されます。
ここまで、Spring BatchでのKafkaItemReaderの基本的な使い方を見てきました。次に、テストコードの書き方を見てみましょう。
