Dockerネットワーク

概要
Dockerコンテナは隔離された環境で実行されるため、デフォルトでは互いに通信できません。しかし、複数のコンテナを1つのDockerネットワークに接続することで、相互に通信が可能になります。この記事では、異なるコンテナ間の通信を実現するためのネットワーク設定方法について探ります。
ネットワークの種類
Dockerネットワークは、目的に応じてbridge、host、overlayなどのさまざまなネットワークドライバーをサポートしています。
bridge: 単一ホスト内の複数のコンテナ間で通信を可能にします。host: コンテナをホストコンピュータと同じネットワークで実行するために使用されます。overlay: 複数のホスト上で実行されるコンテナ間のネットワーキングに使用されます。
ネットワークの作成
docker network createコマンドを使用して、新しいDockerネットワークを作成しましょう。
docker network create my-net
新しく追加されたネットワークは、docker network lsコマンドを使用して確認できます。-dオプションを指定しなかったため、デフォルトのbridgeネットワークとして作成されたことが確認できます。
ネットワークの詳細
docker network inspectコマンドを使用して、新しく追加されたネットワークの詳細を確認しましょう。
docker network inspect my-net
[
{
"Name": "my-net",
"Id": "05f28107caa4fc699ea71c07a0cb7a17f6be8ee65f6001ed549da137e555b648",
"Created": "2022-08-02T09:05:20.250288712Z",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.18.0.0/16",
"Gateway": "172.18.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {},
"Options": {},
"Labels": {}
}
]
Containersセクションを確認すると、このネットワークに接続されているコンテナがないことがわかります。
コンテナをネットワークに接続する
まず、oneという名前のコンテナを実行しましょう。
docker run -it -d --name one busybox
# af588368c67b8a273cf63a330ee5191838f261de1f3e455de39352e0e95deac4
コンテナを実行する際に--networkオプションを指定しない場合、デフォルトでbridgeネットワークに接続されます。
busyboxは、テスト目的に最適な軽量のコマンドラインライブラリであり、Dockerが公式に提供しています。
docker network inspect bridge
#...
"Containers": {
"af588368c67b8a273cf63a330ee5191838f261de1f3e455de39352e0e95deac4": {
"Name": "one",
"EndpointID": "44a4a022cc0f5fb30e53f0499306db836fe64da15631f2abf68ebc74754d9750",
"MacAddress": "02:42:ac:11:00:02",
"IPv4Address": "172.17.0.2/16",
"IPv6Address": ""
}
},
#...
]
次に、docker network connectコマンドを使用して、oneコンテナをmy-netネットワークに接続しましょう。
docker network connect my-net one
my-netネットワークの詳細を再確認すると、oneコンテナがContainersセクションに追加され、IPアドレス172.18.0.2が割り当てられていることがわかります。
docker network inspect my-net
[
{
"Name": "my-net",
"Id": "05f28107caa4fc699ea71c07a0cb7a17f6be8ee65f6001ed549da137e555b648",
"Created": "2022-08-02T09:05:20.250288712Z",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.18.0.0/16",
"Gateway": "172.18.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {
"af588368c67b8a273cf63a330ee5191838f261de1f3e455de39352e0e95deac4": {
"Name": "one",
"EndpointID": "ac85884c9058767b037b88102fe6c35fb65ebf91135fbce8df24a173b0defcaa",
"MacAddress": "02:42:ac:12:00:02",
"IPv4Address": "172.18.0.2/16",
"IPv6Address": ""
}
},
"Options": {},
"Labels": {}
}
]
コンテナをネットワークから切断する
コンテナは同時に複数のネットワークに接続できます。oneコンテナは最初にbridgeネットワークに接続されていたため、現在はmy-netとbridgeの両方のネットワークに接続されています。
docker network disconnectコマンドを使用して、oneコンテナをbridgeネットワークから切断しましょう。
docker network disconnect bridge one
2つ目のコンテナを接続する
次に、twoという名前のコンテナをmy-netネットワークに接続しましょう。
今回は、コンテナを実行する際に--networkオプションを使用して接続するネットワークを指定します。
docker run -it -d --name two --network my-net busybox
# b1509c6fcdf8b2f0860902f204115017c3e2cc074810b330921c96e88ffb408e
my-netネットワークの詳細を確認すると、twoコンテナがIPアドレス172.18.0.3を割り当てられて接続されていることがわかります。
docker network inspect my-net
[
{
"Name": "my-net",
"Id": "05f28107caa4fc699ea71c07a0cb7a17f6be8ee65f6001ed549da137e555b648",
"Created": "2022-08-02T09:05:20.250288712Z",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.18.0.0/16",
"Gateway": "172.18.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {
"af588368c67b8a273cf63a330ee5191838f261de1f3e455de39352e0e95deac4": {
"Name": "one",
"EndpointID": "ac85884c9058767b037b88102fe6c35fb65ebf91135fbce8df24a173b0defcaa",
"MacAddress": "02:42:ac:12:00:02",
"IPv4Address": "172.18.0.2/16",
"IPv6Address": ""
},
"b1509c6fcdf8b2f0860902f204115017c3e2cc074810b330921c96e88ffb408e": {
"Name": "two",
"EndpointID": "f6e40a7e06300dfad1f7f176af9e3ede26ef9394cb542647abcd4502d60c4ff9",
"MacAddress": "02:42:ac:12:00:03",
"IPv4Address": "172.18.0.3/16",
"IPv6Address": ""
}
},
"Options": {},
"Labels": {}
}
]
コンテナ間のネットワーキング
2つのコンテナがネットワーク上で通信できるかどうかをテストしましょう。
まず、oneコンテナからtwoコンテナにpingコマンドを使用してpingを送ります。コンテナ名をホスト名として使用できます。
docker exec one ping two
# PING two (172.18.0.3): 56 data bytes
# 64 bytes from 172.18.0.3: seq=0 ttl=64 time=0.114 ms
# 64 bytes from 172.18.0.3: seq=1 ttl=64 time=0.915 ms
次に、twoコンテナからoneコンテナにpingを送ります。
docker exec two ping one
# PING one (172.18.0.2): 56 data bytes
# 64 bytes from 172.18.0.2: seq=0 ttl=64 time=0.108 ms
# 64 bytes from 172.18.0.2: seq=1 ttl=64 time=0.734 ms
# 64 bytes from 172.18.0.2: seq=2 ttl=64 time=0.270 ms
# 64 bytes from 172.18.0.2: seq=3 ttl=64 time=0.353 ms
# 64 bytes from 172.18.0.2: seq=4 ttl=64 time=0.371 ms
両方のコンテナがスムーズに通信できることが確認できました。
ネットワークの削除
最後に、docker network rmコマンドを使用してmy-netネットワークを削除しましょう。
docker network rm my-net
# Error response from daemon: error while removing network: network my-net id 05f28107caa4fc699ea71c07a0cb7a17f6be8ee65f6001ed549da137e555b648 has active endpoints
削除しようとしているネットワークにアクティブなコンテナが存在する場合、ネットワークは削除されません。
その場合、ネットワークを削除する前に、そのネットワークに接続されているすべてのコンテナを停止する必要があります。
docker stop one two
# one
# two
docker network rm my-net
# my-net
ネットワークのクリーンアップ
ホスト上で複数のコンテナを実行していると、コンテナが接続されていないネットワークが残ることがあります。そのような場合、docker network pruneコマンドを使用して、不要なネットワークを一度にすべて削除できます。
docker network prune
WARNING! This will remove all custom networks not used by at least one container.
Are you sure you want to continue? [y/N] y
結論
この記事では、さまざまなdocker networkコマンドについて探りました:
lscreateconnectdisconnectinspectrmprune
ネットワークの理解は、Dockerコンテナを扱う際に重要です。データベースのコンテナ化やコンテナクラスタリングの実装など、複数のコンテナを効果的に管理するための重要なスキルです。

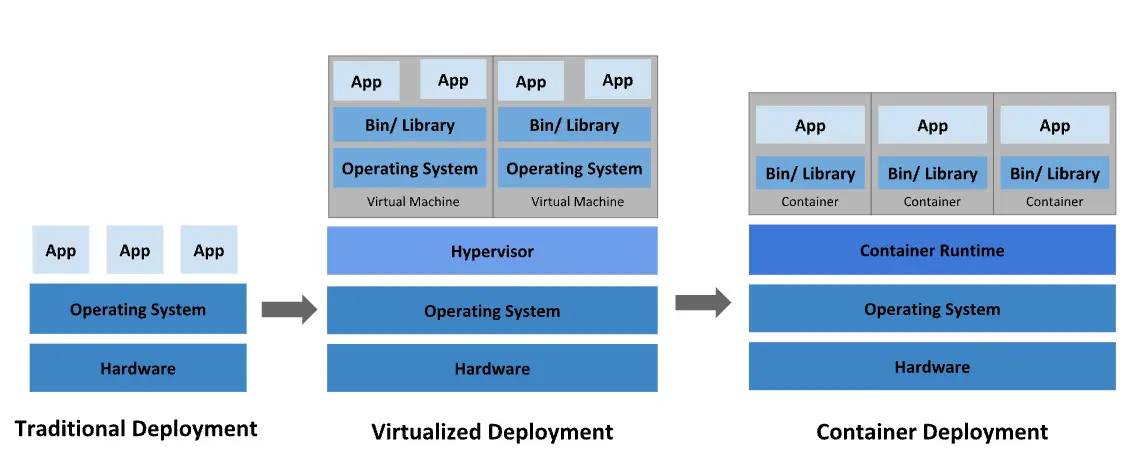 誰もが一度はDockerを検索したときに見たことがある画像
誰もが一度はDockerを検索したときに見たことがある画像
 アクセス成功!
アクセス成功!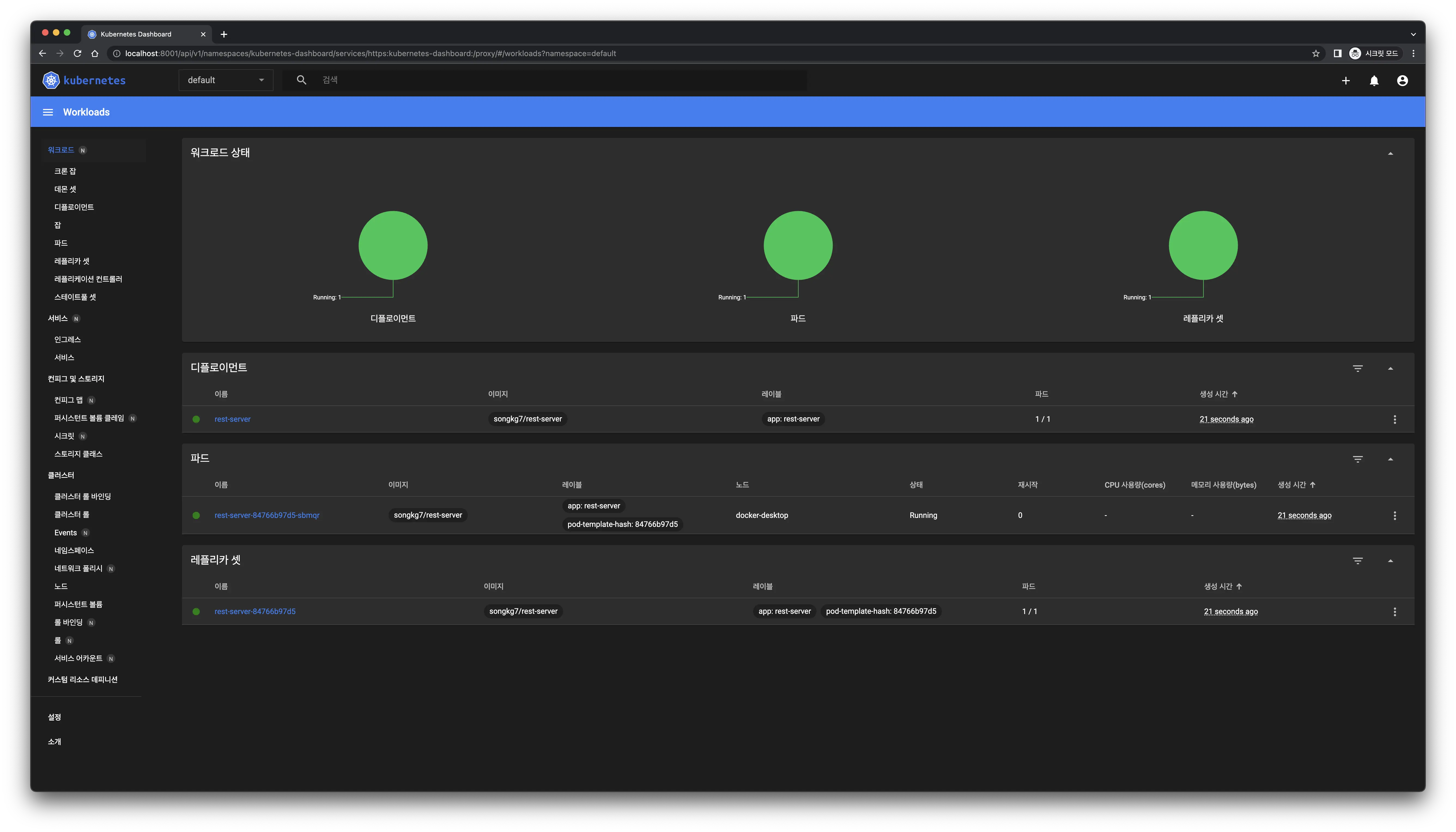 デプロイメント作成後、ダッシュボードが即座に更新されます。
デプロイメント作成後、ダッシュボードが即座に更新されます。


 ほぼ1ヶ月かかってやっと解決しました...😢
ほぼ1ヶ月かかってやっと解決しました...😢