On a Mac, when you press and hold a specific key for a while, a special character input window like umlauts may appear. This can be quite disruptive when using editors like Vim for code navigation.
After running the above command and restarting the application, the special character input window, such as umlauts, will no longer appear and key repetition will be enabled.
Since Docker containers run in isolated environments, they cannot communicate with each other by default. However, connecting multiple containers to a single Docker network enables them to communicate. In this article, we will explore how to configure networks for communication between different containers.
Let's create a new Docker network using the docker network create command.
docker network create my-net
The newly added network can be verified using the docker network ls command, which confirms that it was created as a default bridge network since the -d option was not specified.
A container can be connected to multiple networks simultaneously. Since the one container was initially connected to the bridge network, it is currently connected to both the my-net and bridge networks.
Let's disconnect the one container from the bridge network using the docker network disconnect command.
Let's test if the two containers can communicate with each other over the network.
First, let's use the ping command from the one container to ping the two container. Container names can be used as hostnames.
dockerexec one ping two # PING two (172.18.0.3): 56 data bytes # 64 bytes from 172.18.0.3: seq=0 ttl=64 time=0.114 ms # 64 bytes from 172.18.0.3: seq=1 ttl=64 time=0.915 ms
Next, let's ping the one container from the two container.
dockerexec two ping one # PING one (172.18.0.2): 56 data bytes # 64 bytes from 172.18.0.2: seq=0 ttl=64 time=0.108 ms # 64 bytes from 172.18.0.2: seq=1 ttl=64 time=0.734 ms # 64 bytes from 172.18.0.2: seq=2 ttl=64 time=0.270 ms # 64 bytes from 172.18.0.2: seq=3 ttl=64 time=0.353 ms # 64 bytes from 172.18.0.2: seq=4 ttl=64 time=0.371 ms
Finally, let's remove the my-net network using the docker network rm command.
docker network rm my-net # Error response from daemon: error while removing network: network my-net id 05f28107caa4fc699ea71c07a0cb7a17f6be8ee65f6001ed549da137e555b648 has active endpoints
If there are active containers running on the network you are trying to remove, it will not be deleted.
In such cases, you need to stop all containers connected to that network before deleting the network.
docker stop one two # one # two docker network rm my-net # my-net
When running multiple containers on a host, you may end up with networks that have no containers connected to them. In such cases, you can use the docker network prune command to remove all unnecessary networks at once.
docker network prune WARNING! This will remove all custom networks not used by at least one container. Are you sure you want to continue? [y/N] y
In this article, we explored various docker network commands:
ls
create
connect
disconnect
inspect
rm
prune
Understanding networks is essential when working with Docker containers, whether for containerizing databases or implementing container clustering. It is crucial to have a good grasp of networking as a key skill for managing multiple containers effectively.
Docker containers are completely isolated by default, which means that data inside a container cannot be accessed from the host machine. This implies that the container's lifecycle is entirely dependent on its internal data. In simpler terms, when a container is removed, its data is also lost.
So, what should you do if you need to permanently store important data like logs or database information, independent of the container's lifecycle?
You can also use tools like DBeaver or DataGrip to create users and databases.
When you're done, you can stop the container with docker stop postgres. Checking the container list with docker ps -a will show that the container is stopped but not removed.
$ dockerps-a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 5c72a3d21021 postgres "docker-entrypoint.s…"54 seconds ago Exited (0)43 seconds ago postgres
In this state, you can restart the container with docker start postgres and the data will still be there.
Let's verify this.
Using the \list command in PostgreSQL will show that the testdb database still exists.
The subsequent steps are the same as those without using volumes. Now, even if you completely remove the container using docker rm, the data will remain in the volume and won't be lost.
As mentioned earlier, for long-term storage of log files or backup data, you can use volumes to ensure data persistence independent of the container's lifecycle.
We have explored what Docker volumes are and how to use them through a PostgreSQL example. Volumes are a key mechanism for data management in Docker containers. By appropriately using volumes based on the nature of the container, you can manage data safely and easily, which can significantly enhance development productivity once you get accustomed to it. For more detailed information, refer to the official documentation.
Starting from Gradle 7.4, a feature has been added that allows you to aggregate multiple Jacoco test reports into a single, unified report. In the past, it was very difficult to view the test results across multiple modules in one file, but now it has become much more convenient to merge these reports.
In the case of a Gradle multi-project setup, there is an issue where packages that were properly excluded in a single project are not excluded in the aggregate report.
By adding the following configuration, you can generate a report that excludes specific packages.
The jvm-test-suite plugin, which is introduced alongside jacoco-aggregation-report in Gradle, also seems very useful. Since these plugins are complementary, it would be beneficial to use them together.
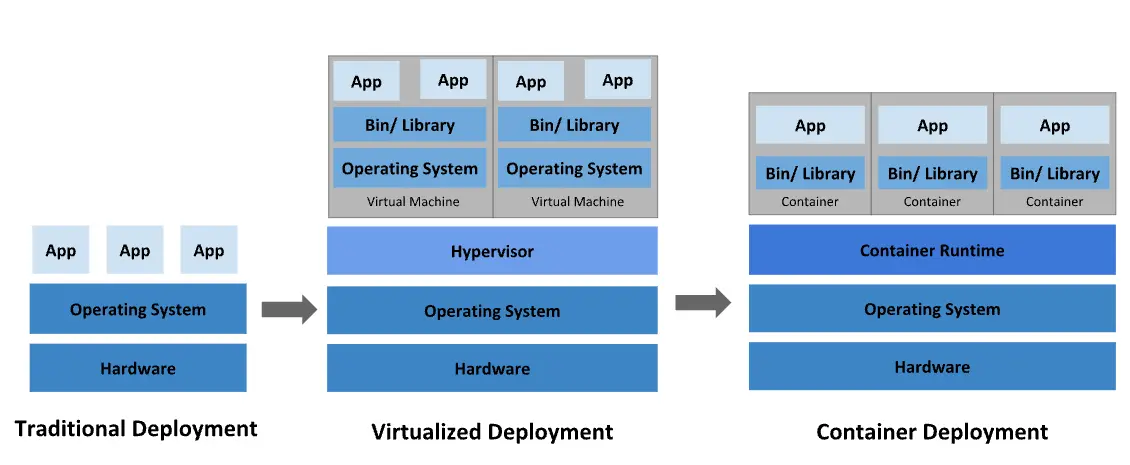
A containerization technology that allows you to create and use Linux containers, and also the name of the largest company supporting this technology as well as the name of the open-source project.
The image everyone has seen at least once when searching for Docker
Introduced in 2013, Docker has transformed the infrastructure world into a container-centric one. Many applications are now deployed using containers, with Dockerfiles created to build images and deploy containers, becoming a common development process. In the 2019 DockerCon presentation, it was reported that there were a staggering 105.2 billion container image pulls.
Using Docker allows you to handle containers like very lightweight modular virtual machines. Additionally, containers can be built, deployed, copied, and moved from one environment to another flexibly, supporting the optimization of applications for the cloud.
As long as the container runtime is installed, Docker containers guarantee the same behavior anywhere. For example, team member A using Windows OS and team member B using MacOS are working on different OSs, but by sharing the image through a Dockerfile, they can see the same results regardless of the OS. The same goes for deployment. If the container has been verified to work correctly, it will operate normally without additional configuration wherever it is run.
Docker's containerization approach focuses on the ability to decompose, update, or recover parts of an application without needing to break down the entire application. Users can share processes among multiple applications in a microservices-based approach, similar to how service-oriented architecture (SOA) operates.
Each Docker image file consists of a series of layers, which are combined into a single image.
Docker reuses these layers when building new containers, making the build process much faster. Intermediate changes are shared between images, improving speed, scalability, and efficiency.
Docker-based containers can reduce deployment time to mere seconds. Since there is no need to boot the OS to add or move containers, deployment time is significantly reduced. Moreover, the fast deployment speed allows for cost-effective and easy creation and deletion of data generated by containers, without users needing to worry about whether it was done correctly.
In short, Docker technology emphasizes efficiency and offers a more granular and controllable microservices-based approach.
When deploying with Docker, images are used with tags. For example, if you deploy using version 1.2 of an image, and version 1.1 of the image is still in the repository, you can simply run the command without needing to prepare the jar file again.
docker run --name app image:1.2 docker stop app ## Run version 1.1 docker run --name app image:1.1
Package the jar file to be deployed on the local machine.
Transfer the jar file to the production server using file transfer protocols like scp.
Write a service file using systemctl for status management.
Run the application with systemctl start app.
If multiple apps are running on a single server, the complexity increases significantly in finding stopped apps. The process is similarly cumbersome when running multiple apps on multiple servers, requiring commands to be executed on each server, making it a tiring process.
Use a Dockerfile to create an image of the application. → Build ⚒️
Push the image to a repository like Dockerhub or Gitlab registry. → Shipping🚢
Run the application on the production server with docker run image.
You don't need to waste time on complex path settings and file transfer processes. Docker works in any environment, ensuring it runs anywhere and uses resources efficiently.
Docker is designed to manage single containers effectively. However, as you start using hundreds of containers and containerized apps, management and orchestration can become very challenging. To provide services like networking, security, and telemetry across all containers, you need to step back and group them. This is where Kubernetes1 comes into play.
Developers can find Docker extremely useful in almost any situation. In fact, Docker often proves superior to traditional methods in development, deployment, and operations, so Docker containers should always be a top consideration.
When you need a development database like PostgreSQL on your local machine.
When you want to test or quickly adopt new technologies.
When you have software that is difficult to install or uninstall directly on your local machine (e.g., reinstalling Java on Windows can be a nightmare).
When you want to run the latest deployment version from another team, like the front-end team, on your local machine.
When you need to switch your production server from NCP to AWS.
Using Docker containers allows for convenient operations while solving issues that arise with traditional deployment methods. Next, we'll look into the Dockerfile, which creates an image of your application.
There are various ways to run Kubernetes, but the official site uses minikube for demonstration. This article focuses on utilizing Kubernetes using Docker Desktop. If you want to learn how to use minikube, refer to the official site.
One major drawback is that sometimes the command to view the dashboard causes hang-ups. This issue is the primary reason why I am not using minikube while writing this article.
When a deployment is created, pods are also generated simultaneously.
kubectl get pods -o wide
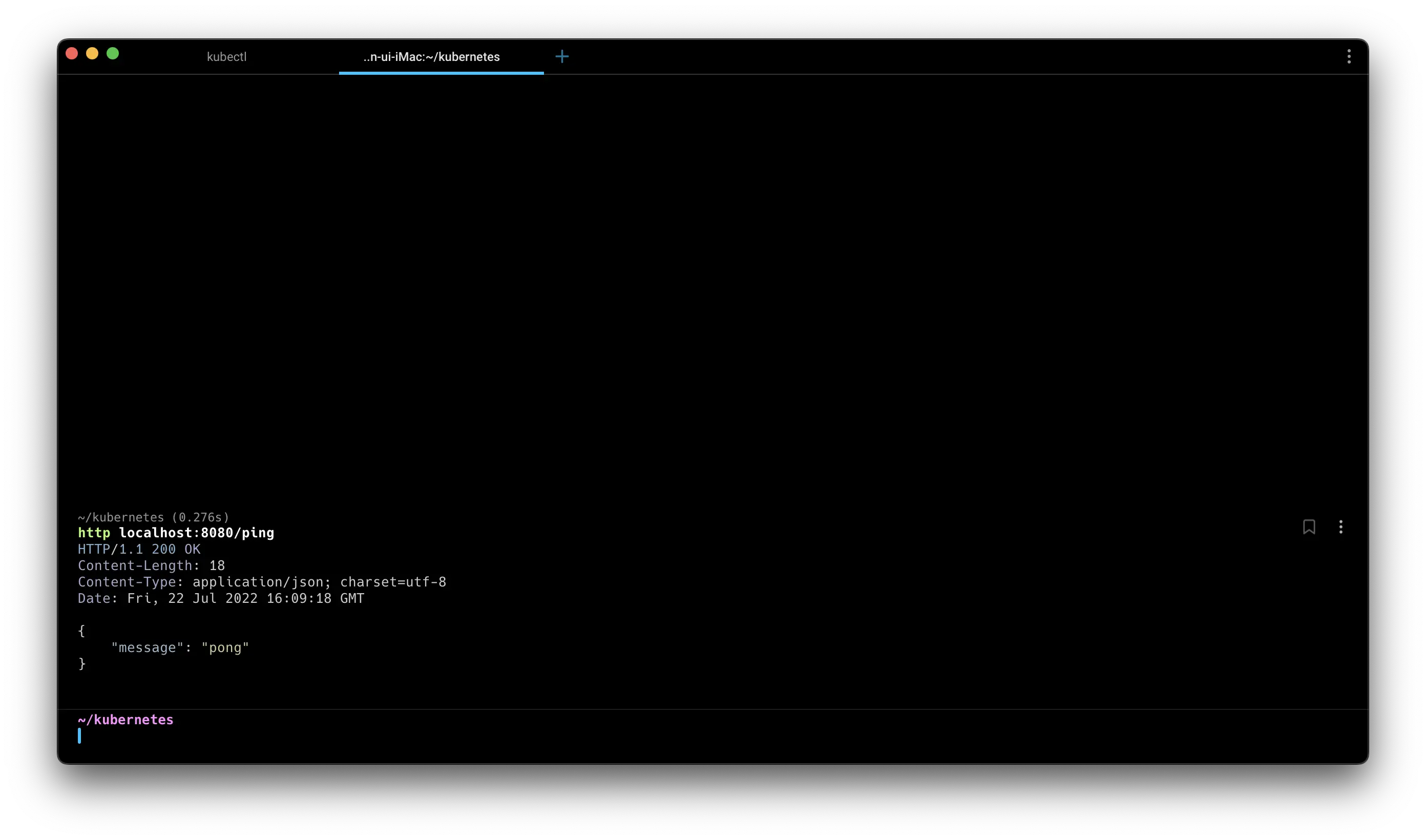
Having confirmed that everything is running smoothly, let's send a request to our web server. Instead of using curl, we will use httpie1. If you are more comfortable with curl, feel free to use it.
http localhost:8080/ping
Even though everything seems to be working fine, why can't we receive a response? 🤔
This is because our service is not exposed to the outside world yet. By default, Kubernetes pods can only communicate internally. Let's make our service accessible externally.
// Java Collection that implements Iterable. publicinterfaceCollection<E>extendsIterable<E>
First-class collections are a very useful way to handle objects. However, despite the name "first-class collection," it only holds Collection as a field and is not actually a Collection, so you cannot use the various methods provided by Collection. In this article, we introduce a way to make first-class collections more like a real Collection using Iterable.
It's not bad, but AssertJ provides various methods to test collections.
has..
contains...
isEmpty()
You cannot use these convenient assert methods with first-class collections because they do not have access to them due to not being a Collection.
More precisely, you cannot use them because you cannot iterate over the elements without iterator(). To use iterator(), you just need to implement Iterable.
By implementing Iterable, you can use much richer functionality. The implementation is not difficult, and it is close to extending functionality, so if you have a first-class collection, actively utilize Iterable.
If you are a developer who frequently uses Linux, you probably use the curl command often. It is an essential command for sending external API requests from a server, but it has the disadvantage of poor readability in the output. HTTPie is an interesting tool that can alleviate this drawback, so let's introduce it.
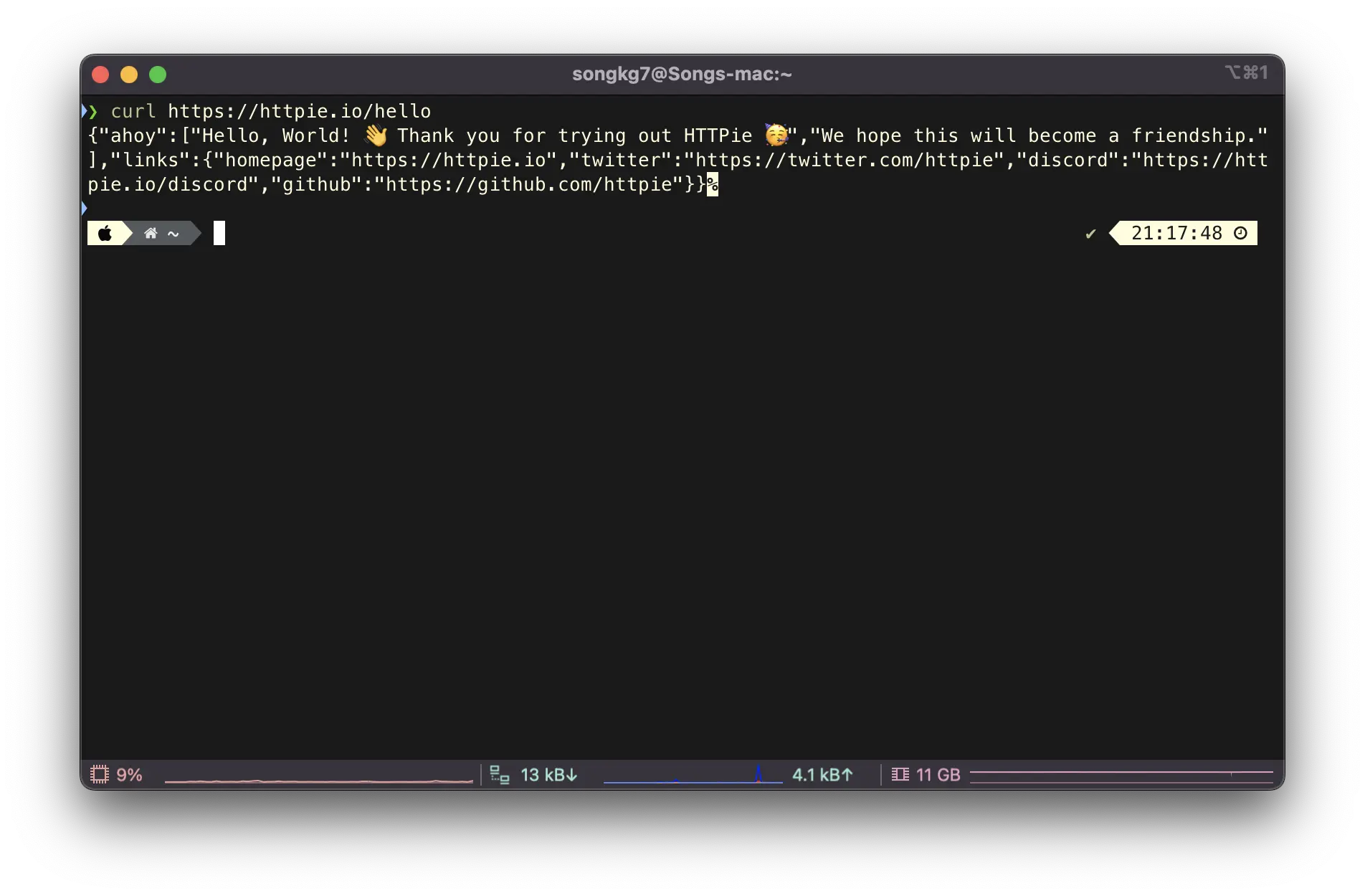
First, here is how you would send a GET request using curl.
curl https://httpie.io/hello
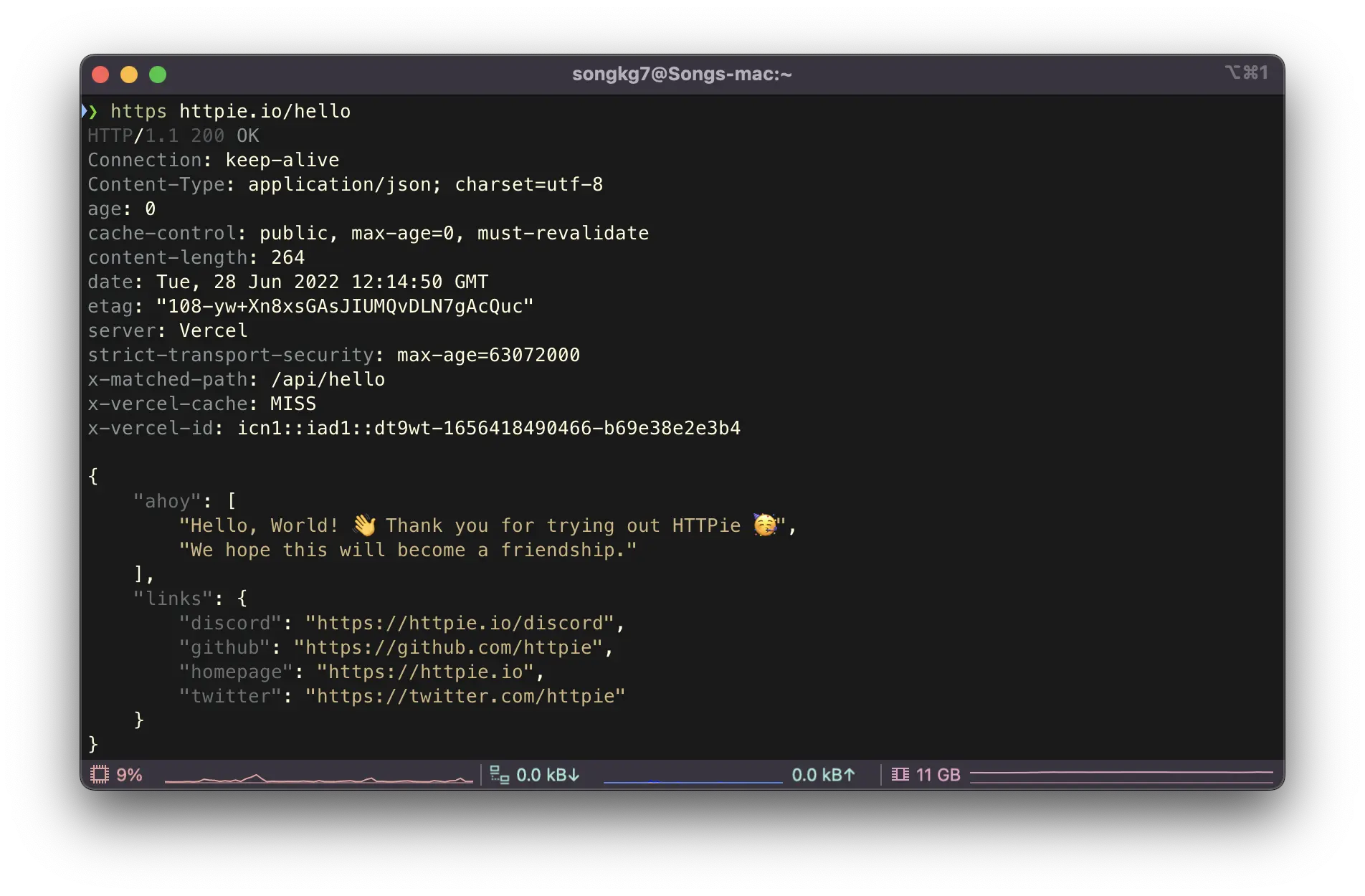
Now, let's compare it with HTTPie.
https httpie.io/hello
The readability is much better in every aspect of the command. The response and header values are included by default, so you can get various information at a glance without using separate commands.
Note that https and http are distinguished in the command.
http localhost:8080
You can send a POST request as described on the official website.
http -a USERNAME POST https://api.github.com/repos/httpie/httpie/issues/83/comments body='HTTPie is awesome! :heart:'
Various other features are explained on GitHub, so if you make good use of them, you can greatly improve productivity.
When you search for getter/setter on Google, you'll find a plethora of articles. Most of them explain the reasons for using getter/setter, often focusing on keywords like encapsulation and information hiding.
The common explanation is that by declaring field variables as private to prevent external access and only exposing them through getter/setter, encapsulation is achieved.
However, does using getter/setter truly encapsulate data?
In reality, getter/setter cannot achieve encapsulation at all. To achieve encapsulation, one should avoid using getters and setters. To understand this, it is necessary to have a clear understanding of encapsulation.
Encapsulation in object-oriented programming has two aspects: bundling an object's attributes (data fields) and behaviors (methods) together and hiding some of the object's implementation details internally. - Wikipedia
Encapsulation means that the external entities should not have complete knowledge of an object's internal attributes.
As we have learned, encapsulation dictates that external entities should not know the internal attributes of an object. However, getter/setter blatantly exposes the fact that a specific field exists to the outside world. Let's look at an example.
publicclassStudent{ privateString name; privateint age; publicStringgetName(){ return name; } publicvoidsetName(String name){ this.name = name; } publicintgetAge(){ return age; } publicvoidsetAge(int age){ this.age = age; } publicStringintroduce(){ returnString.format("My name is %s and I am %d years old.", name, age); } }
classStudentTest{ @Test voidstudent(){ Student student =newStudent(); student.setName("John"); student.setAge(20); String introduce = student.introduce(); assertThat(student.getName()).isEqualTo("John"); assertThat(student.getAge()).isEqualTo(20); assertThat(introduce).isEqualTo("My name is John and I am 20 years old."); } }
From outside the Student class, it is evident that it has attributes named name and age. Can we consider this state as encapsulated?
If the age attribute were to be removed from Student, changes would need to be made everywhere getter/setter is used. This creates strong coupling.
True encapsulation means that modifications to an object's internal structure should not affect the external entities, except for the public interface.
Let's try to hide the internal implementation.
publicclassStudent{ privateString name; privateint age; publicStudent(String name,int age){ this.name = name; this.age = age; } publicStringintroduce(){ returnString.format("My name is %s and I am %d years old.", name, age); } }
classStudentTest{ @Test voidstudent(){ Student student =newStudent("John",20); String introduce = student.introduce(); assertThat(introduce).isEqualTo("My name is John and I am 20 years old."); } }
Now, the object does not expose its internal implementation through the public interface. It is not possible to know what data it holds, prevent it from being modified, and only communicate through messages.
Encapsulation is a crucial topic in object-oriented design, emphasizing designs that are not dependent on external factors. Opinions vary on the level of encapsulation, with some advocating against using both getter and setter and others suggesting that using getter is acceptable.
Personally, I believe in avoiding getter usage as much as possible, but there are situations, especially in testing, where having getters or setters can make writing test code easier. Deciding on the level of encapsulation depends on the current situation and the purpose of the code being developed.
Good design always emerges through the process of trade-offs.
I had registered the sitemap.xml for my blog to ensure it gets indexed by Google, but all I was getting was an error message saying 'sitemap not found'. Finally, I managed to resolve it, and I am sharing the method I used.
While this method may not solve every case, it seems worth a try.
Simply run the following command:
curl https://www.google.com/ping\?sitemap\={path to your submitted sitemap}
And then, when you check the search console again...!


 The image everyone has seen at least once when searching for Docker
The image everyone has seen at least once when searching for Docker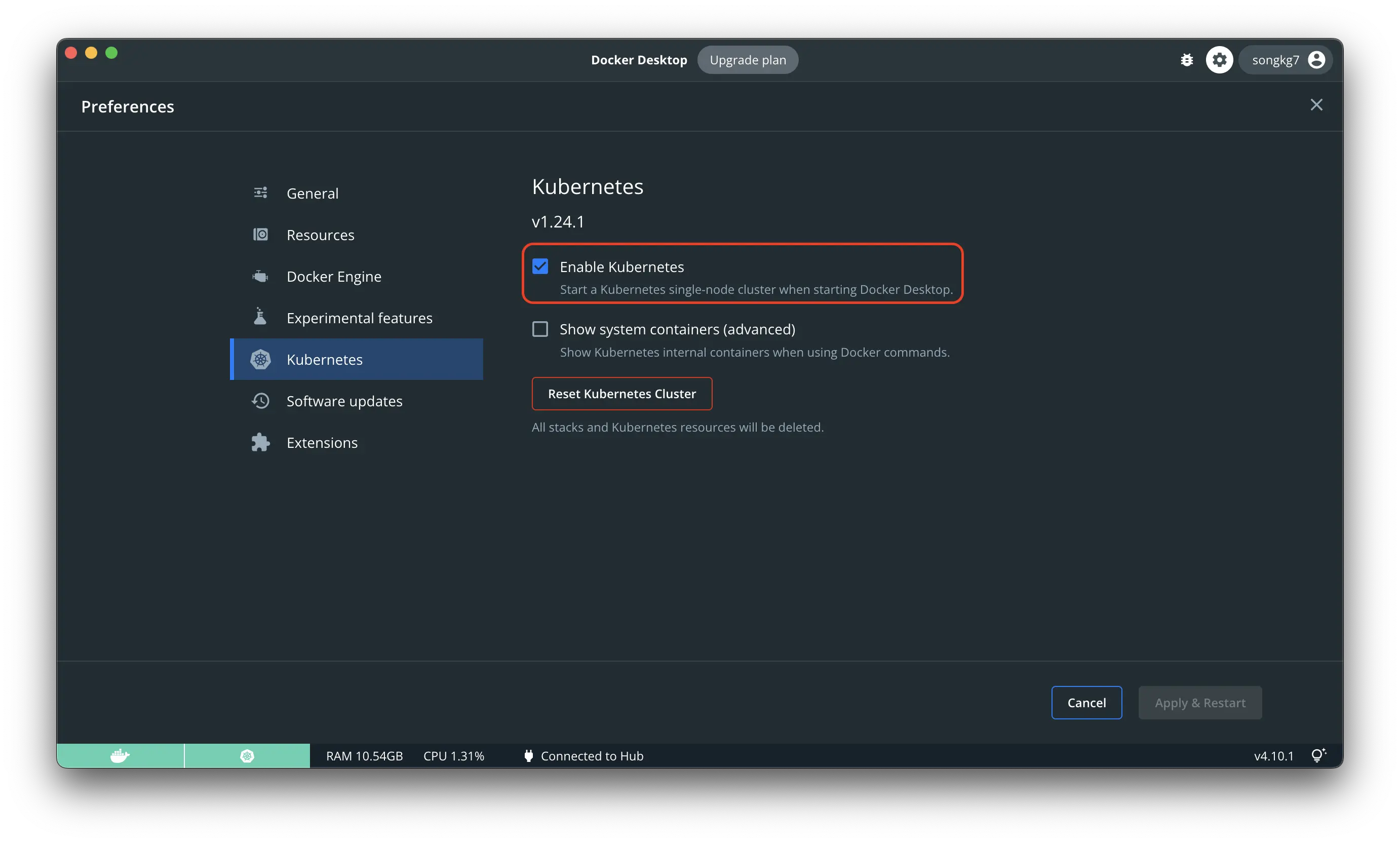
 Successful access!
Successful access!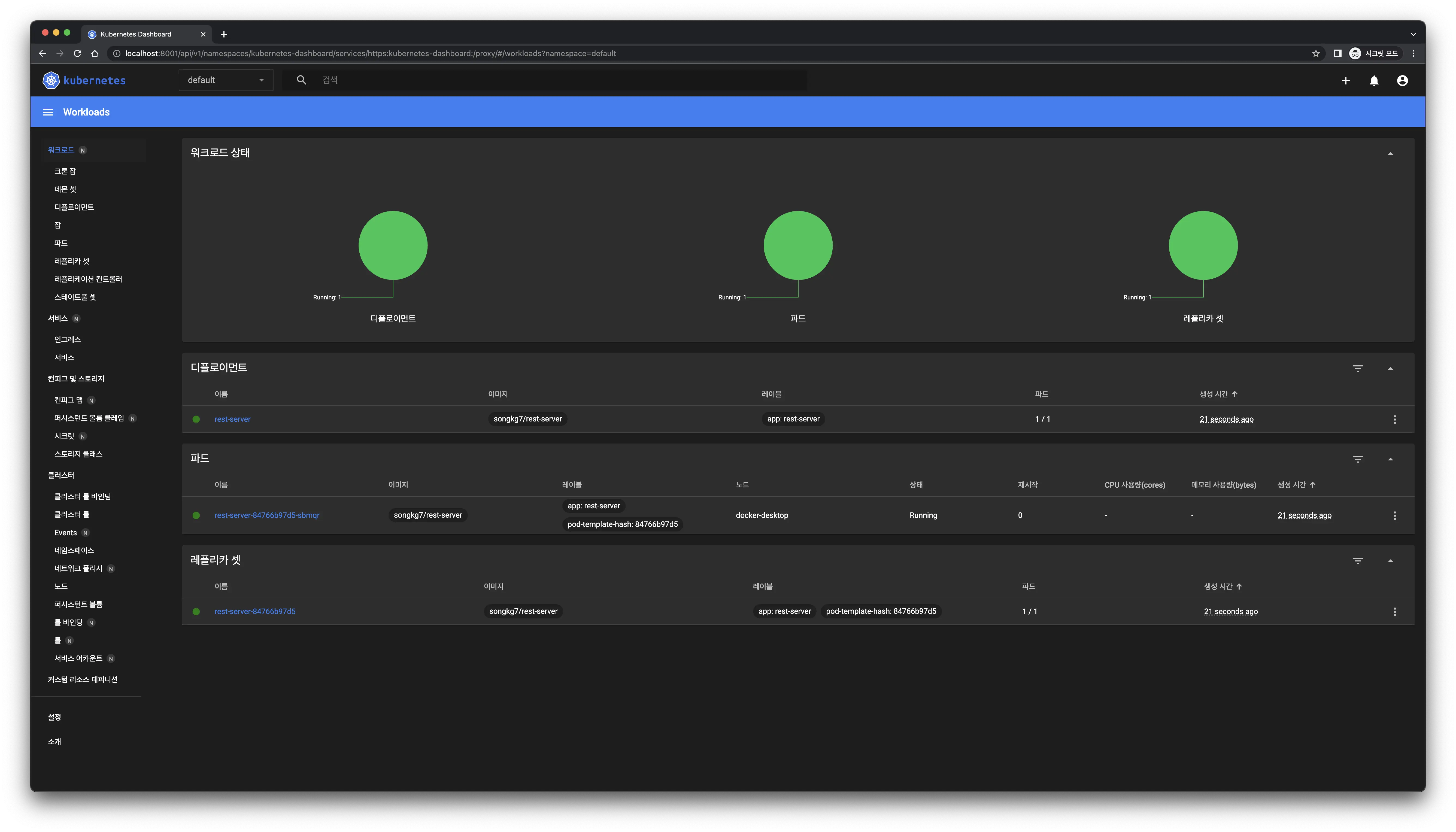 The dashboard updates immediately upon deployment creation.
The dashboard updates immediately upon deployment creation.


 Finally resolved after almost a month...😢
Finally resolved after almost a month...😢