Make Testing Easy and Convenient with Fixture Monkey

"Write once, Test anywhere"
Fixture Monkey is a testing object creation library being developed as open source by Naver. The name seems to be inspired by Netflix's open source tool, Chaos Monkey. By generating test fixtures randomly, it allows you to experience chaos engineering in practice.
Since I first encountered it about 2 years ago, it has become one of my favorite open source libraries. I even ended up writing two articles about it.
I haven't written any additional articles as there were too many changes with each version update, but now that version 1.x has been released, I am revisiting it with a fresh perspective.
While my previous articles were based on Java, I am now writing in Kotlin to align with current trends. The content of this article is based on the official documentation with some added insights from my actual usage.
Why Fixture Monkey is Needed
Let's examine the following code to see what issues exist with the traditional approach.
I used JUnit5, which is familiar to Java developers, for the examples. However, personally, I recommend using Kotest in a Kotlin environment.
data class Product (
val id: Long,
val productName: String,
val price: Long,
val options: List<String>,
val createdAt: Instant,
val productType: ProductType,
val merchantInfo: Map<Int, String>
)
enum class ProductType {
ELECTRONICS,
CLOTHING,
FOOD
}
@Test
fun basic() {
val actual: Product = Product(
id = 1L,
price = 1000L,
productName = "productName",
productType = ProductType.FOOD,
options = listOf(
"option1",
"option2"
),
createdAt = Instant.now(),
merchantInfo = mapOf(
1 to "merchant1",
2 to "merchant2"
)
)
// The preparation process is lengthy compared to the test purpose
actual shouldNotBe null
}
Challenges of Test Object Creation
Looking at the test code, it feels like there is too much code to write just to create objects for assertion. Due to the nature of the implementation, if properties are not set, a compilation error occurs, so even meaningless properties must be written.
When the preparation required for assertion in test code becomes lengthy, the meaning of the test purpose in the code can become unclear. The person reading this code for the first time would have to examine even seemingly meaningless properties to see if there is any hidden significance. This process increases developers' fatigue.
Difficulty in Recognizing Edge Cases
When directly setting properties to create objects, many edge cases that could occur in various scenarios are often overlooked because the properties are fixed.
val actual: Product = Product(
id = 1L, // What if the id becomes negative?
// ...omitted
)
To find edge cases, developers have to set properties one by one and verify them, but in reality, it is often only after runtime errors occur that developers become aware of edge cases. To easily discover edge cases before errors occur, object properties need to be set with a certain degree of randomness.
Issues with the Object Mother Pattern
To reuse test objects, a pattern called the Object Mother pattern involves creating a factory class to generate objects and then executing test code using objects created from that class.
However, this method is not favored because it requires continuous management not only of the test code but also of the factory. Furthermore, it does not help in identifying edge cases.
Using Fixture Monkey
Fixture Monkey elegantly addresses the issues of reusability and randomness as mentioned above. Let's see how it solves these problems.
First, add the dependency.
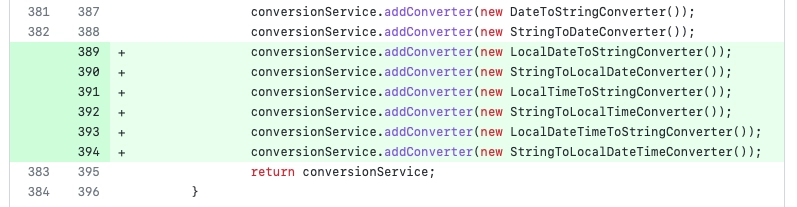
testImplementation("com.navercorp.fixturemonkey:fixture-monkey-starter-kotlin:1.0.13")
Apply KotlinPlugin() to ensure that Fixture Monkey works smoothly in a Kotlin environment.
@Test
fun test() {
val fixtureMonkey = FixtureMonkey.builder()
.plugin(KotlinPlugin())
.build()
}
Let's write a test again using the Product class we used before.
data class Product (
val id: Long,
val productName: String,
val price: Long,
val options: List<String>,
val createdAt: Instant,
val productType: ProductType,
val merchantInfo: Map<Int, String>
)
enum class ProductType {
ELECTRONICS,
CLOTHING,
FOOD
}
@Test
fun test() {
val fixtureMonkey = FixtureMonkey.builder()
.plugin(KotlinPlugin())
.build()
val actual: Product = fixtureMonkey.giveMeOne()
actual shouldNotBe null
}
You can create an instance of Product without the need for unnecessary property settings. All property values are filled randomly by default.
 Fills in multiple properties nicely
Fills in multiple properties nicely
Post Condition
However, in most cases, specific property values are required. For example, in the example, the id was generated as a negative number, but in reality, id is often used as a positive number. There might be a validation logic like this:
init {
require(id > 0) { "id should be positive" }
}
After running the test a few times, if the id is generated as a negative number, the test fails. The fact that all values are randomly generated makes it particularly useful for finding unexpected edge cases.

Let's maintain the randomness but restrict the range slightly to ensure the validation logic passes.
@RepeatedTest(10)
fun postCondition() {
val fixtureMonkey = FixtureMonkey.builder()
.plugin(KotlinPlugin())
.build()
val actual = fixtureMonkey.giveMeBuilder<Product>()
.setPostCondition { it.id > 0 } // Specify property conditions for the generated object
.sample()
actual.id shouldBeGreaterThan 0
}
I used @RepeatedTest to run the test 10 times.

You can see that all tests pass.
Setting Various Properties
When using postCondition, be cautious as setting conditions too narrowly can make object creation costly. This is because the creation is repeated internally until an object that meets the condition is generated. In such cases, it is much better to use setExp to fix specific values.
val actual = fixtureMonkey.giveMeBuilder<Product>()
.setExp(Product::id, 1L) // Only the specified value is fixed, the rest are random
.sample()
actual.id shouldBe 1L
If a property is a collection, you can use sizeExp to specify the size of the collection.
val actual = fixtureMonkey.giveMeBuilder<Product>()
.sizeExp(Product::options, 3)
.sample()
actual.options.size shouldBe 3
Using maxSize and minSize, you can easily set the maximum and minimum size constraints for a collection.
val actual = fixtureMonkey.giveMeBuilder<Product>()
.maxSizeExp(Product::options, 10)
.sample()
actual.options.size shouldBeLessThan 11
There are various other property setting methods available, so I recommend exploring them when needed.
Conclusion
Fixture Monkey really resolves the inconveniences encountered while writing unit tests. Although not mentioned in this article, you can create conditions in the builder and reuse them, add randomness to properties, and help developers discover edge cases they may have missed. As a result, test code becomes very concise, and the need for additional code like Object Mother disappears, making maintenance easier.
Even before the release of Fixture Monkey 1.x, I found it very helpful in writing test code. Now that it has become a stable version, I hope you can introduce it without hesitation and enjoy writing test code.


 No way!
No way! Fortunately, our Pandora's box contains only 0s and 1s, with no other hardships or challenges.
Fortunately, our Pandora's box contains only 0s and 1s, with no other hardships or challenges.
 JVM Instruction Set showing the bytecode for invokevirtual
JVM Instruction Set showing the bytecode for invokevirtual